Franz’s Newsletter 2.24.25 - Reasoning Models & the Compute Paradigm Shift
Each week I'll share insights on the latest trends across tech-enabled verticals. Stay informed & follow along!

R1, Inference Compute, and the Model Size Debate
The last few weeks have been a whirlwind in AI land. DeepSeek’s recent R1 release created massive ripple effects across the tech landscape— perhaps most noticeably when the DeepSeek app suddenly soared to #1 in the app store (is this legit? Or the result of farming downloads via bots?).
What is DeepSeek? DeepSeek is an AI dedicated to refining large, complex models into smaller, more efficient versions, while incorporating their own research-driven breakthroughs. These smaller models preserve much of the original capability but operate faster with a lower cost. Just a couple weeks ago, DeepSeek launched its R1 model— a reasoning-focused AI model designed to tackle tasks that require logic, problem-solving, and decision-making . . . and it’s quite good!
The team claims its final training run only cost <$10m. But it’s important to note that this figure excludes several significant expenses (i.e., research experiments leading to final successful run, failed runs along the way, capital expenditures, data costs, etc.). There’s probably many more costs embedded in the true “fully loaded” cost. For a fair apples-to-apples comparison with today’s state-of-the-art models, a more accurate approach would be to compare DeepSeek’s quoted cost to the successful training run cost of OpenAI’s o1 model.
This has sparked A LOT of questions - too much to unpack entirely. So, I’ll focus on two key aspects at the core of the discussion R1 ignited:
Reasoning Models
Inference-time compute
Let’s start with reasoning. OpenAI ushered in this paradigm with it’s o-series models. o3 mini-high currently leads the pack. Google boasts Gemini 2.0 Flash Thinking, X recently released Grok3 on Feb-13, R1 is DeepSeek’s reasoning model, and there will certainly be many more.
But what is a reasoning model? Put simply, it is designed to emulate logical thinking. Unlike models that recognize patterns or repeat “learned” information harnessed during training, reasoning models SOLVE problems and follow chains of thoughts to arrive at a comprehensive conclusion. Think of it as an AI that doesn’t just “know information”— it knows how to figure things out when faced with new challenges.
Closely tied to reasoning models is the concept of inference-time compute. Inference-time compute is the computational power required for a model to “think through” a problem and produce a step-by-step answer, after it has been trained. The process involves taking your input, breaking it down, reasoning about it, and generating a coherent response.
One way to visualize this is to imagine the model as a problem-solver working through steps in a chain of thought. Suppose you ask how many pies a baker has left after selling some. First, the model interprets your question, identifies key details (e.g., initial number of pies, how many were sold, what calculation is needed), and then works through the problem step by step. Generally, one can think of reasoning models as models that “check their work as they go”.
Every stage of this process—understanding the question, reasoning through it, and verifying the answer—demands computational power. And the more complex the task / longer the chain of thought, the more compute is required. This is especially true for reasoning models like o3 and R1, which are intended for handling multi-step problems & tasks that require careful validation.
What’s particularly exciting is how these models don’t just “spit out” answers - they simulate thinking. They track intermediate steps, check for contradictions, and will sometimes even revisit earlier assumptions if something seems off. This makes inference significantly more compute-intensive compared to simpler models that rely on pattern recognition or single-step responses.
As AI applications demand more sophisticated reasoning—whether it’s autonomous agents making decisions, chatbots handling complex queries, or systems engaging in real-time interactions—the compute required during inference is beginning to match, or even surpass, the resources once reserved for training. This evolution lies at the core of the paradigm shift reshaping AI today
Until now, discussions around compute needs and constraints have largely focused on scaling up pre-training. The approach was straightforward: throw more compute and data at the training phase to make large models more capable. While inference has always required compute, the lion’s share of resources historically went toward training. That balance, however, is beginning to shift.
This evolving dynamic is partly why debates around Nvidia intensified late last year, as conversations about “scaling laws ending” gained traction. People started questioning whether simply adding more compute could still meaningfully boost model performance. And if that strategy no longer held, what would it mean for the massive investments being poured into Nvidia’s hardware?
While the scaling laws debate is still very much alive, I think it’s causing many to miss the bigger picture: What happens to compute demand as the AI landscape shifts toward reasoning and inference-time compute? That’s the real question. Here’s how Jensen put it:

Jensen’s point is clear: we’re entering a new era—one where inference-time compute (or test-time scaling) takes center stage.
Inference-time compute is positioned to drive a massive surge in compute demand. As more AI applications hit production, they’ll need substantial inference power to serve real-world users in real time. Take AI-powered agents—programs that autonomously interact with users or systems to complete tasks—they’re heavily dependent on inference-time compute. The more agents running in parallel, the more steps they take, the more “thinking” they do… the more compute gets consumed. And as AI adoption scales, that demand doesn’t just grow linearly—it compounds. It’s also worth calling out: reasoning models shift a significant chunk of that compute load to inference time, amplifying the effect even further.
Something that’s been on my mind lately is that cheaper models (e.g., R1 and many others) will drive an explosion of AI adoption across various use cases. Why not explore and prototype more when a tool gets cheaper? Naturally, when something gets cheaper and more accessible, demand / consumption increases. And in this case, increased consumption leads to. . . more inference-time compute!
If you agree with the “scaling laws are ending” debate, then you might believe that we’ll witness a decrease in pre-training spend. But, even in this case, I’d say the reduction in spend quickly gets absorbed and surpassed by increased demand attributable to inference-time compute. Said differently: if all models get cheaper, demand will increase (i.e., more inference). There is, however, a question of timing on how long it will take for inference-time compute to compensate for smaller pre-training spend. I personally don’t see market-leading AI labs pulling back spend, because I don’t think scaling laws are fading (after all R1 wouldn’t exist without the OpenAI’s foundational models) and I think we’ll concurrently see inference-time compute start to boom.
However, I think this sparks a new side to the aforementioned debate— the smaller / distilled model will generally be more efficient; fewer layers and parameters enable these models with shorter compute time due to fewer calculations necessary to arrive at a conclusion. This furnishes users with a solution that is cheaper and faster to use in real-world use cases vs their larger peers. Although, when it comes to complex tasks, extensive models tend to be more powerful and accurate.
So, I’d say there’s a healthy debate regarding whether the future will resemble concentration around smaller / distilled, domain-specific models, or larger, more powerful models.
I haven’t landed on a firm stance in the small vs. large model debate yet, but my gut says the answer falls somewhere in the middle. We wouldn’t have made the progress we’ve seen without large models—that’s undeniable. I don’t think that trajectory changes anytime soon. That said, smaller, domain-specific models are clearly carving out a bigger role. At the end of the day, it feels like a rising tide lifts all boats. It’s really no different from how we make decisions in everyday life. Buying a car? There are budget options and premium ones. Hiring an engineer? Same deal. If we end up leaning more into a smaller model world, the obvious result is cheaper end products—which likely drives up demand. And higher demand, of course, circles back to more compute needs.
One thing I do feel confident about: the pendulum’s going to keep swinging. We’ll probably be blown away by some massive release from the big AI labs soon, and suddenly it’ll be “large models are the future” all over again. Then small models will notch a breakthrough, and the cycle will repeat.
I do think there’s a future where several factors shift. Will the big AI labs stop releasing their full-sized models and instead focus on distilled versions? Do we see everyone move toward open-sourcing? And what happens if the “product” isn’t just the model (via API) anymore, but full-fledged products built around the model? Meta applied early pressure with Llama’s open-sourcing. DeepSeek cranked it up with R1 and its other releases. At this point, if you’re closed source and not delivering state-of-the-art, there’s almost no room left at the table.
The future feels more dynamic than ever—and honestly, I can’t think of a more exciting time to dig in and explore. AI’s growing more powerful by the day while becoming increasingly accessible. That’s a win in my book!
Updates
Software companies are generally valued based on a multiple of their next twelve months (NTM) projected revenue. This revenue multiple serves as a common benchmark, especially since many software companies are still not profitable or don’t generate significant free cash flow. Given the long-term assumptions needed for discounted cash flow (DCF) models, NTM revenue provides a more straightforward approach to compare companies within the sector.
The multiples shown are calculated by dividing enterprise value (market cap + debt - cash) by the company's projected NTM revenue.
EV (Enterprise Value) / NTM Revenue Multiples Over Time (as of Feb-14-25)
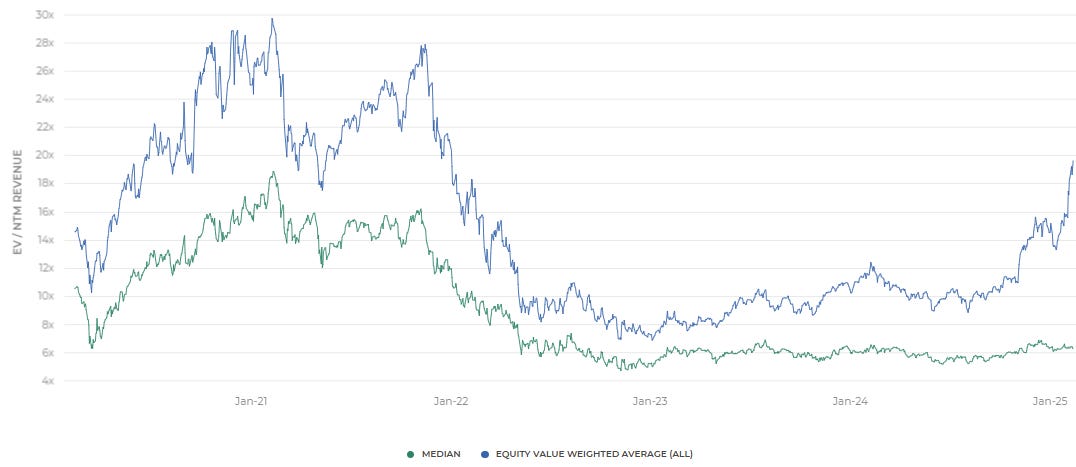
Key Stats:
· Median: 6.3x
· Equity Value Weighted Average: 19.6x
Top 20 EV (Enterprise Value) / NTM Revenue Multiples (as of Feb-14-25)
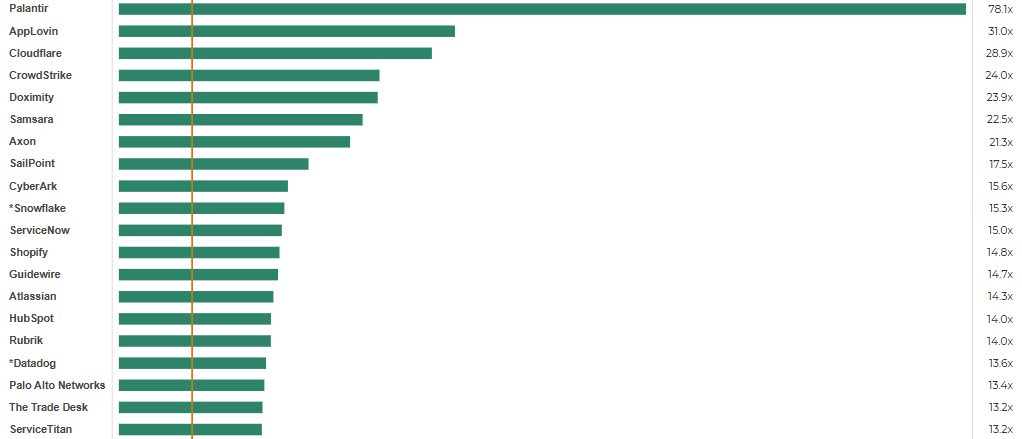
Key Stats:
· Median: 15.2x
· Top 10 Median: 23.2x
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update.