Franz’s Newsletter 5.15.25 - Application Layer: AI Labs Moving Up the Stack
Each week I'll share insights on the latest trends across tech-enabled verticals. Stay informed & follow along!

The Application Layer’s Untapped Value
The big headline in AI land this past week? OpenAI is reportedly in talks to acquire Windsurf (formerly Codeium) in a deal valued at ~$3B. Windsurf is a coding assistant, similar to products from GitHub copilot or Cursor, that helps developers (and increasingly, non-developers) write code faster and more efficiently. In high-level terms, these tools sit on top of a model (like OpenAI’s GPT-4.1 or Anthropic’s Sonnet 3.7) and turn raw model capability into workflow-specific value.
Now, why does this matter? If the Windsurf rumors are even partially true, it signals that model companies are starting to reach up the stack into the application layer. OpenAI has already teased / previewed its upcoming SWE Agent, oriented as a full-blown software engineering assistant. Similarly, Anthropic just rolled out Claude Code. The direction seems pretty clear - we’ll begin to see the AI labs move “up the stack” into the infra / application layer. And there’s a good reason for this shift: if model APIs get commoditized (i.e., prices trend to zero), then AI-focused businesses will need other vectors to garner profits (not revenue, but profits). Owning applications—especially ones built on top of your own models—seems like a natural next step. It does raise an interesting channel conflict question: will the leading AI labs (OpenAI / Anthropic) seek to furnish other coding assistants to compete with their own coding assistant application? Or will they reserve the current top-shelf model for their own applications, while offering an older version via API, to ensure the AI lab is always running the best available model? My guess (for now) is that OpenAI & Anthropic will continue to release current models in API; the incentive to maximize model usage likely outweighs that of protecting first-party apps. But this could change if model companies begin to become more and more application focused. Irrelevant of evolving orientations, I think one reason we’ll start to witness more application acquisitions being announced by model companies is that there may be (for now at least) more profits to be reaped there.
But I think there’s a second (arguably bigger) reason. These applications generate a tremendous amount of DATA. One of OpenAI’s greatest benefits of having ChatGPT is the multi-turn conversation data users produce every day. If you’ve ever been asked to “select your preferred answer” between two outputs, you’ve participated in their data reinforcement loop. Every usage of ChatGPT improves the model. And text data is fairly straightforward - there’s a world of public text data on the prompted interest / subject. The same rings true in the case of code. . . but contrarily, code is not publicly available (there’s a vast amount in open source libraries, but a TON in non-public repositories). One way to train a model like GPT-4.1 or Sonnet 3.7 is to start with a massive volume of code data. The more high-quality data you have, the more capable the model becomes. But what really moves the needle is proprietary code data (and there’s a lot of prop code data). Imagine applying the same feedback loop that powers ChatGPT to code. A developer is prompted with two code suggestions and selects the one that best fits their intent. That signal across millions of interactions creates very valuable data that propels their applications’ & models’ improvement.
And I don’t think code is the “end all be all”. We’ll see the dynamic unfold across other high-value verticals (e.g., biology, life sciences, legal, healthcare, & more), In many of these, the underlying data will skew even more private (i.e., there’s no GitHub for genomic data or clinical workflows). Which makes the application feedback loop—and thus owning the application layer—so critical. Otherwise, you’ll have to pay a fortune to the Scale AIs of the world. The bull case on these data labeling platforms has been that there will always be the “next vertical” where data is scarce, and synthetic data will be worth its weight in gold. So the tradeoff is clear, you can either get code data from your own application, or you can pay Scale to seek developers willing to write structured code for you.
Is OpenAI eyeing Windsurf for the profits? The data? Or something else entirely? Quite exciting times. . . who else might be an acquisition target purely for the data they sit on?
Updates
Software companies are generally valued based on a multiple of their next twelve months (NTM) projected revenue. This revenue multiple serves as a common benchmark, especially since many software companies are still not profitable or don’t generate significant free cash flow. Given the long-term assumptions needed for discounted cash flow (DCF) models, NTM revenue provides a more straightforward approach to compare companies within the sector.
The multiples shown are calculated by dividing enterprise value (market cap + debt - cash) by the company's projected NTM revenue.
EV (Enterprise Value) / NTM Revenue Multiples Over Time (as of May-9-25)
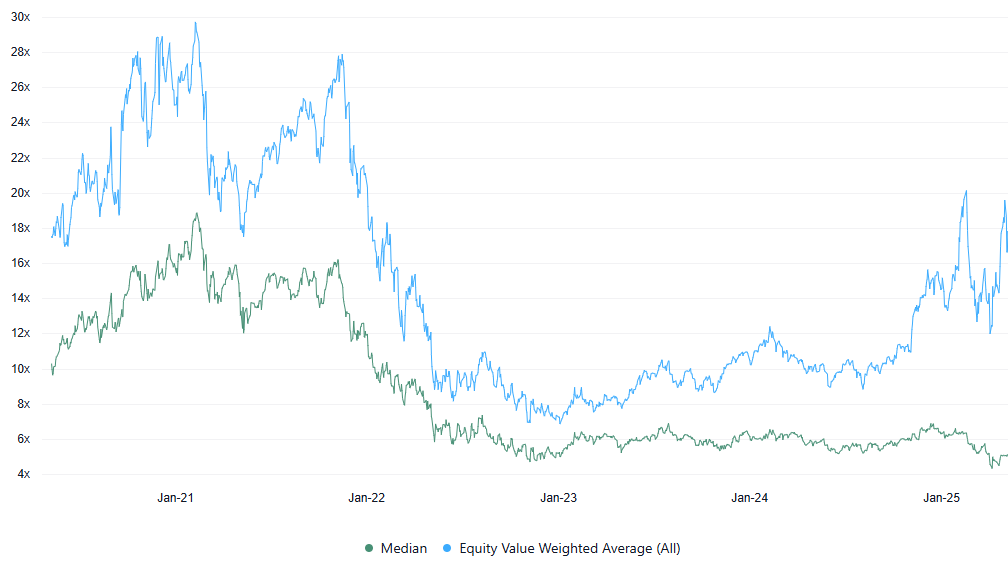
Key Stats:
· Median: 5.1x
· Equity Value Weighted Average: 17.5x
Top 20 EV (Enterprise Value) / NTM Revenue Multiples (as of May-9-25)
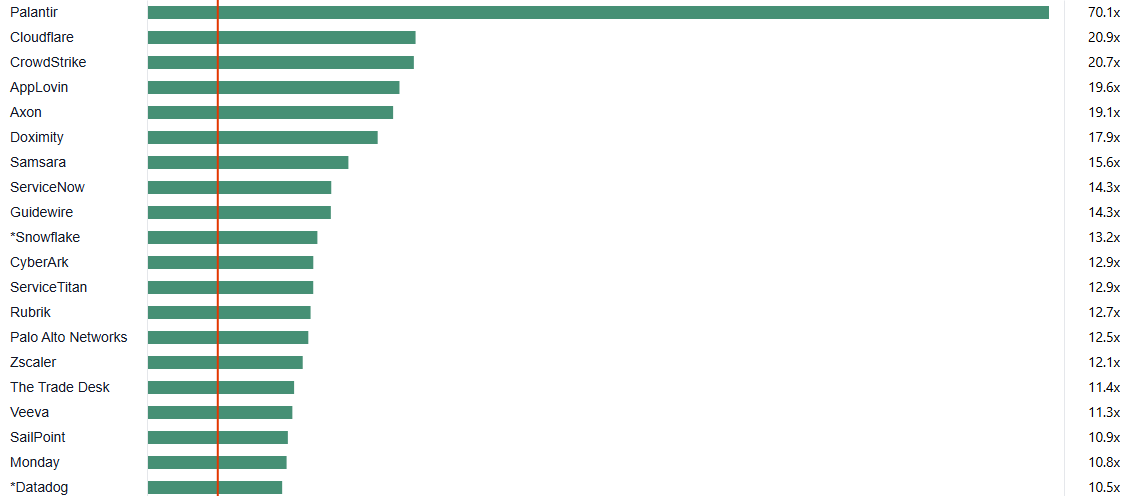
Key Stats:
Median: 13.1x
Top 10 Median: 18.5x
This post and the information presented are intended for informational purposes only. The views expressed herein are the author’s alone and do not constitute an offer to sell, or a recommendation to purchase, or a solicitation of an offer to buy, any security, nor a recommendation for any investment product or service. While certain information contained herein has been obtained from sources believed to be reliable, neither the author nor any of his employers or their affiliates have independently verified this information, and its accuracy and completeness cannot be guaranteed. Accordingly, no representation or warranty, express or implied, is made as to, and no reliance should be placed on, the fairness, accuracy, timeliness or completeness of this information. The author and all employers and their affiliated persons assume no liability for this information and no obligation to update.